Level 2 RAID / RAID 2 / RAID Level 2
RAID 2 tries to get around the 50% disk overhead in the RAID 1. Four decades ago,
R.W. Hamming in his “Error Detecting and Correcting Codes” research paper showed
that if data could be organized so that an error was only likely to affect one bit
in a group, then the error could be detected and corrected with significantly
lower overhead.
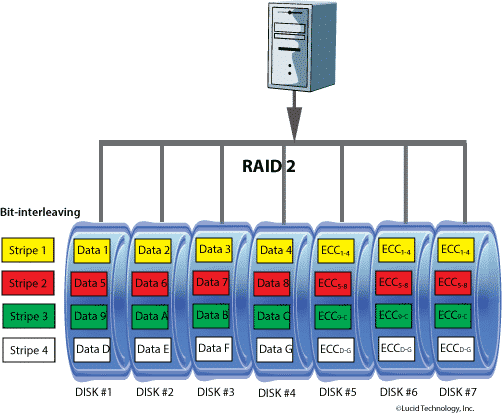
RAID 2 / RAID Level 2 Diagram
RAID 2 takes advantage of the Hamming codes to reduce disk overhead. The
first disk drive contains the first bit in each data group, the second disk
contains the second bit, and so forth. Thus, if each data group is eight
bits, we have eight data drives. We then add one additional drive for each
bit in the Hamming code or ECC (error correcting code). For example, if data
were grouped into bytes, we would need 11 drives – 8 for data and 3 for ECC.
Depending upon the number of data drives and the number of required ECC drives,
the overhead would range from 27% (11 drives total) to 50% (4 drives total).
For a read, all of the data disks must seek before the read starts. For a write,
all of the data drives must seek, the data is read, all of the drives (including
ECC) must seek again, and then the data is written. Thus seek times are going to
be very slow relative to a single drive. However, once the seek has completed,
data transfers are very high. With 8 data drives, the drives will all transmit
data in parallel and the transfer rate of the virtual drive will be 8 times that
of the individual physical drives.
However, keep in mind that the Berkeley papers were written for the mini,
mainframe, and supercomputer environments. Thus RAID 2 overlooks the realities of
the microcomputer environment. The ECC bits in the Hamming code serve two purposes.
They are used to correct the faulty bit, but they are also used to identify
which bit contains the error. In the microcomputer environment, we already know
which bit (drive) has an error due to the internal checksums on the disk and standard
drive and controller error flags. Thus the Hamming codes are too robust for our need
and we pay a penalty for carrying redundant error isolation data.
The Berkeley papers suggest that the data drives could contain 10% more data
by eliminating the internal checksums and allowing the Hamming code to isolate
errors. Such a plan would be expensive though. It would require non-standard low-level
formatting and read/write logic on the drives and would also require that the ECC be
verified for every block of every read. Is all this trouble and expense worthwhile for a
10% increase? If we could simply let the drives manage the error detection and found a
way to convert 2 of the ECC drives in the 8/3 RAID 2 to data drives, we would get a 25%
increase without modifying any off-the-shelf drives.
The following RAID articles describing various RAID levels will show that RAID 3
through RAID 5 allow us to convert all of the ECC drives, except one, to data. Therefore,
RAID 2 cannot be considered a viable alternative and should not be considered for any
commercial implementation.